Удаляем сайт из вебархива
Причины на удаление страниц сайта из всемирного веб-хранилища могут быть самые разные. Но достаточно и того, что вообще-то никто не давал разрешение на сохранение и всеобщий доступ к этим данным. Вебархив делает это по своей инициативе, ни у кого не спрашивая разрешения.
Новый рабочий способ - с 2018 года
Как ни банально, но надо написать в сапорт вебархива и попросить удалить ваш сайт из базы данных.
Форма письма, думаю, значения не имеет, но имеет значение, откуда и кто будет писать. Вот, что мне ответил сапорт (перевод от гугл переводчика, сорян):
Интернет-архив может исключать веб-сайты из Wayback Machine
( web.archive.org ), но мы сначала с уважением просим вас
подтвердить, что вы являетесь владельцем сайта или автором контента, выполнив одно из
следующих действий:
* разместите свой запрос на текущую версию сайта (и отправьте нам ссылку).
* отправьте свой запрос с основного адреса электронной почты, указанного на сайте (если таковой
имеется).
* отправьте запрос с электронной почты регистратора (если он доступен для просмотра в
WHOIS) или электронной почты веб-мастера, указанного на сайте.
* укажите нам, где ваша личная информация (имя, контактное лицо,
образ себя) появляется на сайте таким образом, который идентифицирует вас как владельца
сайта или автора контента, который вы хотите исключить, - в этом
случае мы просим подтвердить вашу личность с помощью проверки действительного идентификатора фотографии
(чувствительного такие данные, как дата рождения, адрес или номер телефона, могут быть
затемнены).
* пересылайте нам сообщение от хостинговой компании или регистратора,
адресованного вам как владельцу домена.
Если ни один из этих вариантов не доступен для вас, сообщите нам об этом в
ответ на это письмо.
Собственно, и вся инструкция.
Самый простой способ: пишите с почты вида почта@вашдомен.ру, либо с другой почты, которая указана в контактах на сайте. Я так и сделал, написал с такой почты, указал ссылку на страницу Контакты и на сайт в вебархиве. Через 4 дня мне ответили, что в течение 1 дня удалят мой сайт из базы. Проверил, действительно, сайт удален: при запросе по домену архив выдает вот такое:
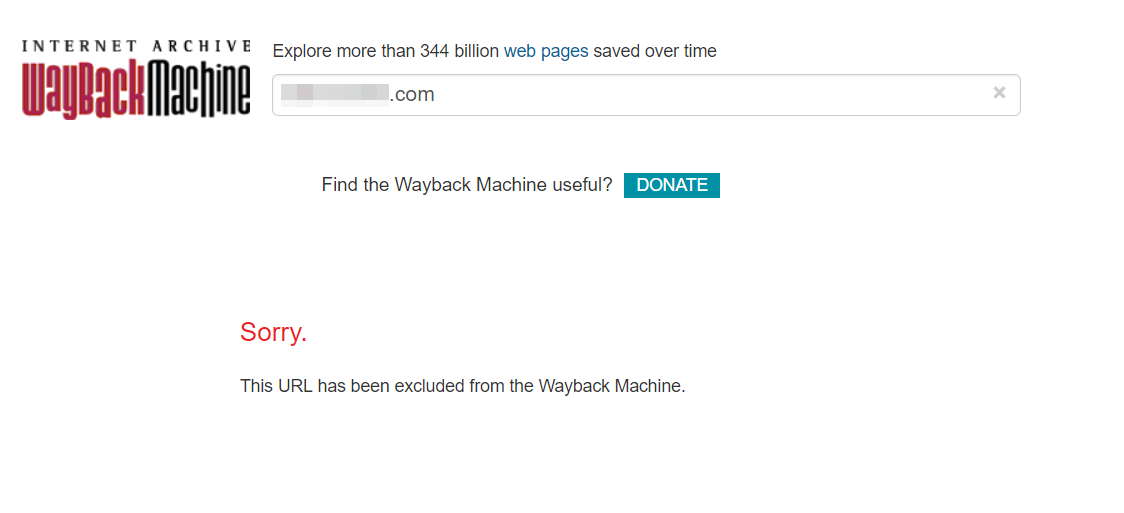
Раньше работал такой простой способ - до 2018 года
Запретить сохранять и показывать данные о вашем сайте можно с помощью специальной директивы, указанной в файле robots.txt
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
Пишут, что достаточно первой директивы для робота ia_archiver, но я на всякий случай прописал и для ia_archiver-web.archive.org
После того, как я добавил эти директивы и зашел в вебархив и вбил свой домен в поиск, сайт пропал из web.archive.org в течение двух дней.
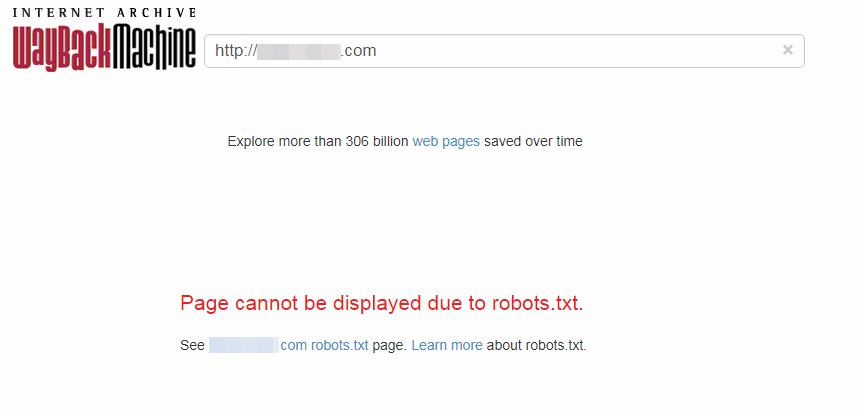
Теперь, если вбить домен в поиск, выдаст следующее сообщение:
Page cannot be displayed due to robots.txt.
See site.com robots.txt page. Learn more about robots.txt.
Ниже скрин.
В некоторых источниках пишут, что достаточно указать директиву:
Disallow: /
И все роботы (поисковые, вебархива и др) перестанут индексировать сайт.
Но я видел сайты с Disallow: /, историю по которым вебархив все равно продолжал выдавать.
Нюансы
- Необходимо иметь доступ к домену, чтобы прописать запрет роботу вебархива. Т.е. если у вас истек срок регистрации домена, то придется продливать. А если кто-то другой успел зарегистрировать домен, то ничего сделать не получится. Разве что писать новому владельцу и просить добавить в robots.txt нужные вам строчки.
- Даже при прописывании нужных директив, web.archive.org не удалит данные о сайте, а лишь перестанет выдавать к ним доступ ПОКА robots.txt доступен. Т.е. опять же, когда закончится срок регистрации домена, вебархив снова выдаст ваш сайт с потрохами. И это не теория, я действительно с этим столкнулся. Поэтому если хотите, чтобы вашего сайта не было в вебархиве - продливайте домен и держите robots.txt доступным.
- При анализе robots.txt в вебмастере Гугла, обнаружилось, что Гугл принимает запрет к индексации роботу ia_archiver, как запрет Googlebot. Поясню скриншотом:
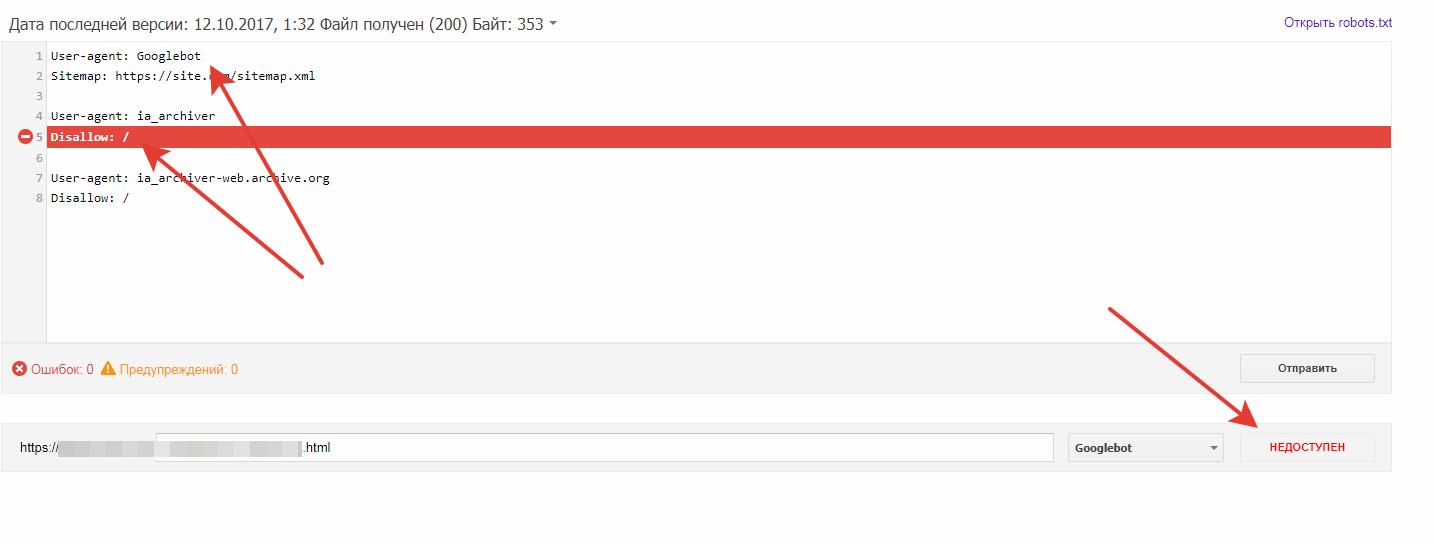
Несмотря на то, что для Googlebot прописана отдельная директива (в которой нет никаких запретов), "Инструмент проверки файла robots.txt" обращает внимание на Disallow: / для ia_archiver и сообщает, что страницы сайта недоступны для индекса Гуглом.
Но сайт из примера все равно нормально проиндексировался в Гугле, так что скорее всего это баг инструмента проверки. Например, инструмент проверки в Яндекс вебмастере показал что с таком robots.txt, все страницы доступны.
Но вы будьте внимательны, и проверяйте как сайт индексируется, если вам это необходимо.
 10
10 10 425
10 425
Комментариев 10